【技术深度】具身智能最难场景的数据炼金术:家庭保洁正在重塑机器人进化路径
我是2019年入行的,当时行业里有个共识:家庭场景五年内不可能落地。五年过去了,这个判断依然成立,但我开始重新理解这句话的含义——不是“做不了”,而是“在等一个契机”。
入行初期的技术判断
当年在实验室里,机器人叠毛巾能稳定在95%成功率就觉得模型很强了。拿到真实家庭测试,三天就崩溃——拖鞋是软的、玩具是随机摆放的、沙发缝隙宽度每家不同。工厂场景的确定性优势在这里被彻底颠覆。
后来我参与过仓储机器人的落地项目,对比之下更清晰:仓库里箱子是标准件,地面是平的,任务是一次次重复的。家庭场景里,机器人在夹鞋的时候会掉,在抓筷子的时候会滑,每一件物品都在考验它对未知物理属性的现场估算能力。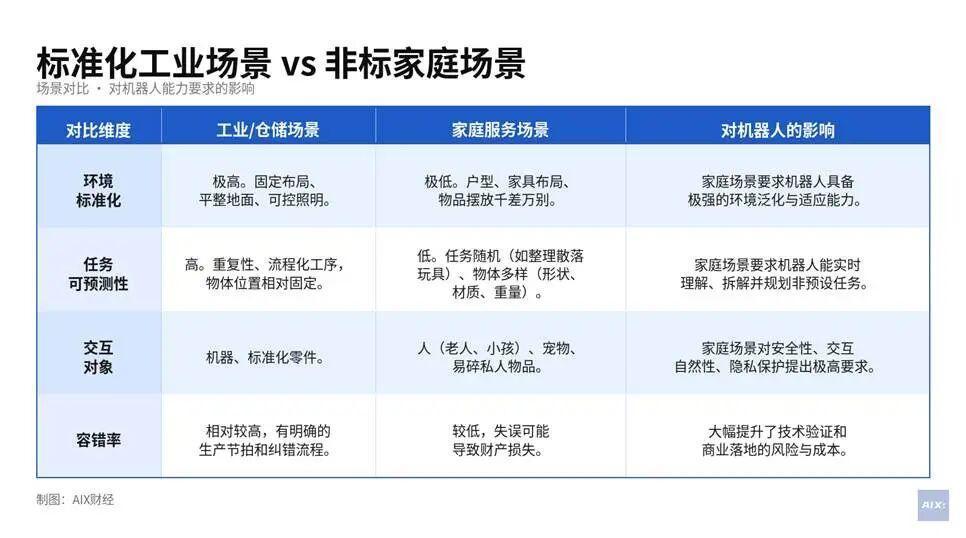
三个改变认知的关键节点
第一个节点是2023年某次行业闭门会。波士顿动力前CEO提到,他们预计五到十年后机器人才会进入家庭。我当时觉得这太保守,现在反而觉得这是务实的判断。
第二个节点是今年初看到自变量的视频。149块钱,机器人+工程师+阿姨组合上门。用户吐槽效率低,但没人注意到一个细节:机器人叠一件衣服十分钟,这十分钟里它经历了什么?夹力调整、角度重算、姿态校准——每一步都是训练样本。
第三个节点是某投资人的一句话:“我们投的不是保洁机器人,是进入家庭场景后持续积累真实物理世界数据的能力。”实验室刷榜没有意义,谁能最早拿到最真实的家庭场景数据,谁的模型就最快进化。
为什么家庭场景数据价值更高
互联网数据可以从网络爬取,成本相对低廉。具身机器人不同,它需要的是物理世界里与真实物体交互产生的行为数据。家庭场景有几个不可替代的优势:
第一是随机性。物品摆放每次不同,任务无法预设,这种随机性产生高质量训练数据。第二是多样性。200个家庭有200种布局、200种物品清单,数据分布足够丰富。第三是失败样本的价值。智源研究院的数据负责人说过,同样动作采100次、100次一模一样,这100条数据等于一条。真正有价值的数据是带随机性的、带失败案例的。
机器人夹鞋掉了,筷子滑了——在工程师眼里这是两条训练样本。这正是家庭场景能提供的核心价值。
方法提炼:如何正确评估家庭场景落地路径
判断一家具身智能公司是否值得投资,可以从三个维度看:
一看是否有真实付费场景。PPT演示和宣传视频不等于商业化,能让用户掏钱才是真本事。二看数据闭环能力。进入家庭的规模决定了数据多样性,数据多样性决定了模型进化速度。三看人机协作设计。机器人不可能完全替代人,但可以承担重复性体力劳动,复杂判断交给人处理。
自变量和58到家的合作模式验证了这套逻辑:机器人+阿姨组合,用户体验有人兜底,同时机器人持续在真实场景里积累数据。深圳上线一个月,阿姨和机器人的配合越来越默契。这个“默契”背后,是数据驱动模型迭代的必然结果。
应用指导:从業者的几点建议
如果你在具身智能行业,别被同行的高光宣传片迷惑。关注点应该放在:谁的机器人真正进了普通人的家,谁在真实场景里持续运转、持续出错、持续改进。
如果你在考虑投资具身智能赛道,问一个问题:这家公司有没有进入家庭场景的真实付费服务?如果有,数据积累速度如何?如果没有,问问为什么还在实验室里刷榜。
家庭场景是具身智能最难的应用场景,同时也是价值最高的场景。字节、阿里、美团同时押注自变量,投的不是现在干活很慢的保洁机器人,而是它进入家庭后持续积累真实物理世界数据的能力。这步棋,比多数同行走得早,但未必走得早就是对的——时间会给出答案。